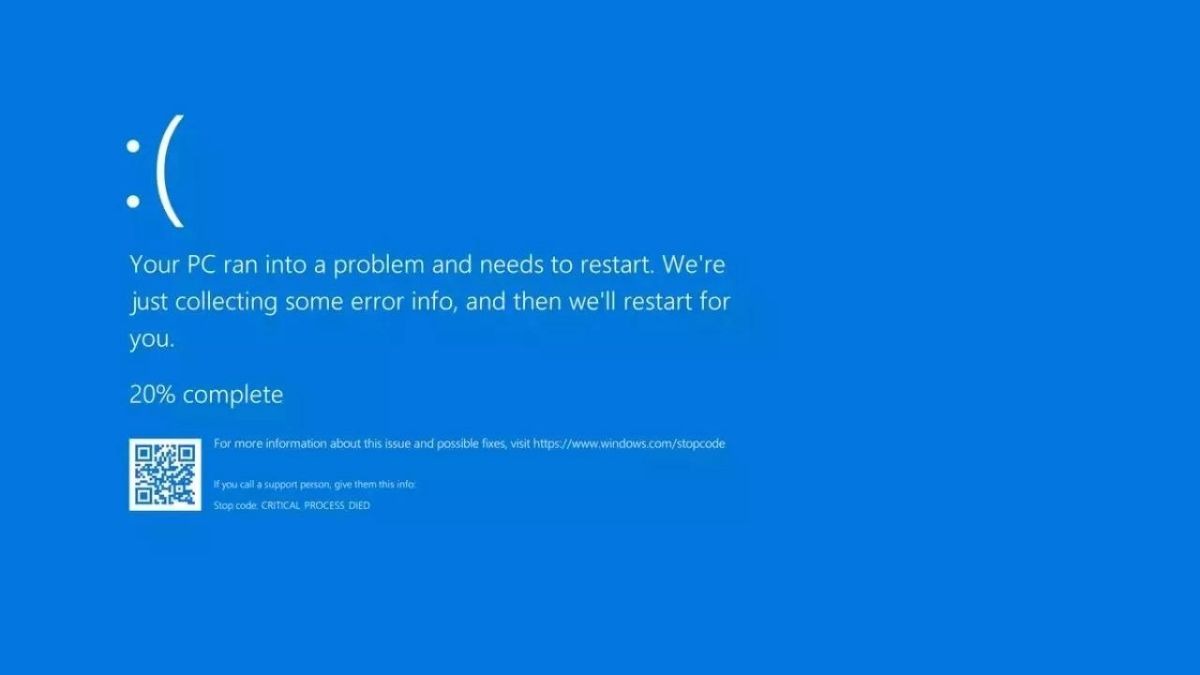
The recent global outage caused by a CrowdStrike software update, affecting industries worldwide, underscores a growing yet often overlooked tech threat: single-point failures. This type of error in one part of a system can create a massive technical disaster, causing widespread disruption across interconnected networks and industries.
Understanding Single-Point Failures
The outage on Friday resulted from a CrowdStrike software bug uploaded to Microsoft operating systems, rather than a malicious attack. This event has drawn attention to the increasing frequency of single-point failures. These failures can lead to extensive disruptions, as seen with global banks, airlines, hospitals, and government offices grappling with the fallout.
Chad Sweet, co-founder and CEO of The Chertoff Group and former Chief of Staff at the Department of Homeland Security, remarked on CNBC, “It’s more frequent even when it’s just routine patching and updates.” This sentiment was echoed by digital boards in Times Square, New York, displaying blue screens or going completely black due to the global communications outage.
The Need for Robust Risk Management
Sweet emphasized the importance of single-point failure risk management, highlighting the necessity for companies to plan and protect against such vulnerabilities. “There’s no software in the world that gets released and doesn’t later need to be patched or updated,” he said. Best security practices for ongoing software maintenance are crucial.
In response to the CrowdStrike outage, companies working with The Chertoff Group are reviewing software development and update standards. Sweet pointed to the SSDF (Secure Software Development Framework) protocols as a potential guide for the industry, especially as Congress starts to scrutinize the issue more closely.
Scenario Planning and Regulatory Insights
Aneesh Chopra, chief strategy officer at Arcadia and former White House chief technology officer, stressed the importance of having contingency plans. “Assuming systems go down, what is plan B? We will see lots more scenario planning,” he told CNBC. This is becoming a priority for business leaders, particularly in critical sectors like energy, banking, healthcare, and airlines.
Chopra also highlighted bipartisan commitment to critical infrastructure and systemic risk issues, noting that technical standards are a hallmark of the U.S. system. Efforts to improve competition could strengthen accountability, ensuring updates are implemented meticulously.
Balancing Regulation and Market Mechanisms
While concerns about overregulation exist, Sweet argued for market-reinforcing mechanisms, such as the insurance industry, to manage risks. “Let the free market do it, through things like the insurance industry, which will reward good actors with lower premiums,” he suggested.
Sweet also advocated for “anti-fragile” organizations, a concept by risk analyst Nassim Nicholas Taleb. These organizations not only recover from disruptions but also thrive and innovate. Sweet believes this approach can help companies outpace competitors and better manage both malicious attacks and unintended consequences from technical updates.
A Wake-Up Call for the Industry
The CrowdStrike incident serves as a wake-up call, emphasizing the critical need for robust risk management and scenario planning. Chopra concluded, “It’s a wakeup call for sure,” highlighting the importance of proactive measures in safeguarding against single-point failures and ensuring the resilience of interconnected systems.
As the industry moves forward, balancing regulation with market-driven solutions will be key to mitigating risks and enhancing the overall security and reliability of global IT infrastructures.
